Add a row to pandas' DataFrame
Quite often, it is needed to fill or modify dataframes with data that gets computed at runtime. This post draws heavily from the stackoverlow question “Add one row to pandas DataFrame”. Here I show the 4 methods that were proposed to append the data and discuss them. A 5th “improper” method operating on columns is added just for sake of comparison with respect to the most efficient option.
If you want just the takeaways:
append()function is not to be used iteratively (still is quite handy for its proper use case: adding a few rows)- index preallocation is a quite good practice, still it is far from being fast enough to allow the creation of DataFrames by looping over rows
Feel free also to jump to the results.
I will just keeping generating data with sequential for loops as in the original source (read more in the digressions).
4+1 ways to add data to a DataFrame
Pandas is extremely expressive and flexible. So flexible that it is not always straightforward choosing which method(s) to use to perform even the simplest operation, as adding a row to an existing DataFrame.
Let’s benchmark 4 approaches:
df.append()
.append(), is certainly the first thing one maybe tempted to use, most probably because of its formal similarity to python’s append over lists. In practice we will benchmark the iteration of this:
# data can be a df, a dict with keys corresponding to df columns and other things.
# Ignore index allow to progressively number row index.
df = df.append(data, ignore_index=True)
Replicating this for a large number of rows is attractive, but the official documentation warns us that this can be:
more computationally intensive than a single concatenate. A better solution is to append those rows to a list and then concatenate the list with the original DataFrame all at once.
We’ll see how true this is.
df.loc() (with and without preallocation)
In modern version of pandas .loc it the de facto standard for accessing data, both label based and with boolean arrays.
Assigning new rows is elegant with .loc and such rows can also be preallocated for a faster access, in fact, if data exists for a given index it is overwritten.
if do_preallocate:
df = pd.DataFrame(index=np.arange(0, num_rows), columns=["A","B"])
else:
df = pd.DataFrame(columns=["A","B"])
df.loc[index] = df.append(data, ignore_index=True)
Of course preallocation requires to know in advance the size of the data.
dict: create all data with a dict and init new dataframe
This is the limiting case of what pandas documentation suggests in case of append except that the whole data is created as a dict and then a new DataFrame is created as follows:
data = [{"A":1, "B":2}, {"A":3, "B":4}]
df = pd.DataFrame(data, columns=["A","B"])
This is IMO not really elegant (requiring 3 data structures) but extremely efficient.
list: create columns by lists and append to the df
As the previous approach, this relies to basic python data structures but involves only the use of lists.
This is way clearer to me but is considered the “+1” bonus method since (i) it requires being able to generate data in advance and (ii) does not stricly cover the original use case.
# lol is a list of list
cols = ["A", "B"]
df = pd.DataFrame(columns=cols)
for i in range(0,len(cols)):
df[cols[i]] = generate_list(i)
Notice also that one could just generate all the lists beforehand and then initialize the df from scratch.
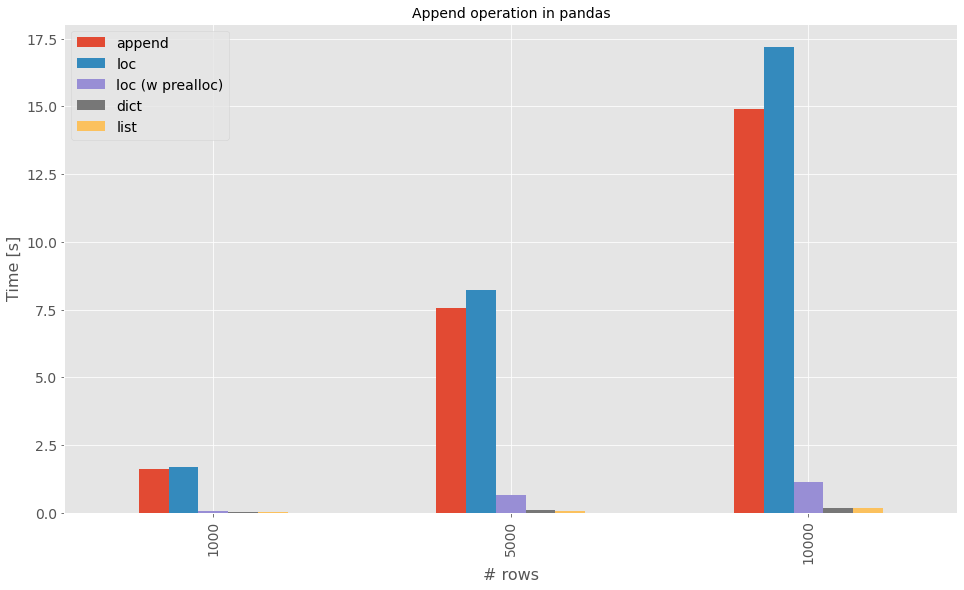
Results
The approaches are tested for 1k, 5k and 10k rows. Results are really clear. Adding a few rows via loc or append is a legitimate use case. Do not abuse it.
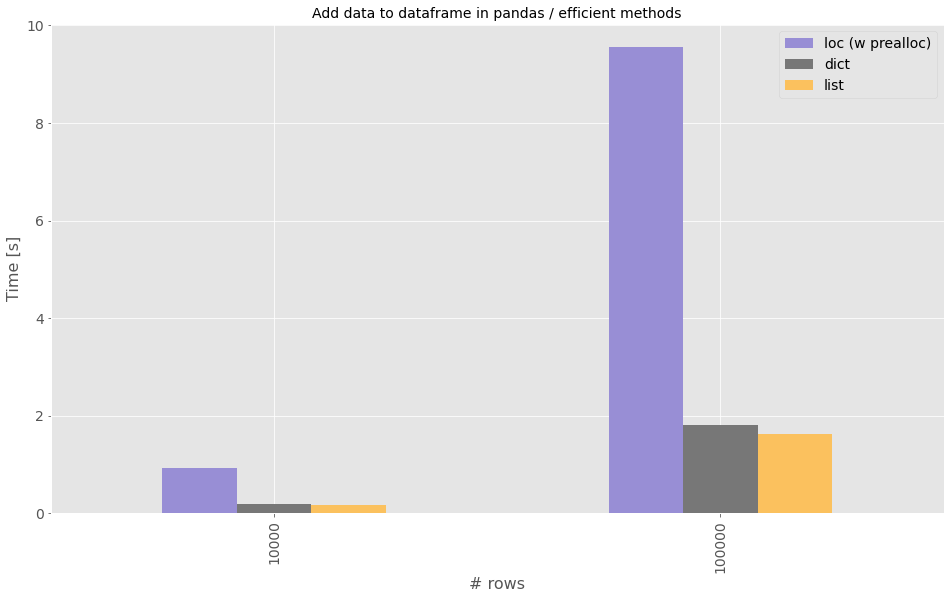
Results, scale up to 100k rows
Now that we know the results on small scale data, it is worth comparing what happens when scaling the 3 most efficient methods from 10k to 100k rows, but take this with a grain of salt, as memory impact is completely disregarded.
The same conclusions apply, preallocated loc is not good enough and dict is the way to good when adding rows to a DataFrame, being comparable with the list approach in terms of times
Digressions
- Vectorizing the part data generation in this experiment would be interesting. Basically, list comprehnsions are faster than for and both should be slower w.r.t. numpy.
- Plots are made with matplotlit backend in pandas since it seems that plotly got a good support for wide-form data only recently while previously operated only on tidy i.e. long-form data. See docs and discussion.